A Developer's Guide to Technical SEO for Your Website
About a year ago, while writing the code for this website, I took a deep dive into how to optimize this site for Search Engine Optimization. While there’s a lot that goes into getting a page to rank, such as domain authority and, of course, the quality of your content, none of it really matters if your website is confusing to navigate, loads slowly, or if the crawlers that index your pages can’t understand what the content is about.
This is where technical SEO comes in; technical SEO is all about making sure that your website is a good experience for both humans and web crawlers (like Googlebot).
In this article, I’m going to give an overview of what you need to do to have good technical SEO for your site - what meta tags matter the most, some easy ways to make your website faster, how to write HTML that crawlers can easily understand, and a few other things!
HTML Metadata
The first thing I want to talk about is the head of an HTML page, which is where the metadata is located. Since this is one of the most important sections of an HTML page for SEO, I’m going to go over all of the HTML elements that you should add to it that directly affect SEO.
Structured Data
Structured data is an important section to add inside the head tag, as it lets search engines easily understand your webpage in a standardized format. You can write this structured data in a JSON format using the schema.org specification, which lets you represent almost any type of page, such as articles, FAQ pages, job postings, etc.
Here’s an example of a structured document for one of my articles. It contains information about the article and about me.
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "The Inner Workings of Python Dataclasses Explained",
"image": "https://jacobpadilla.com/articles/blog_posts/python-dataclass-internals/static/python-dataclass-internals.png",
"datePublished": "2024-12-24T05:57:09Z",
"dateModified": "2024-12-24T05:57:09Z",
"description": "Discover how Python dataclasses work internally! Learn how to use __annotations__ and exec() to make our own dataclass decorator!",
"author": {
"@type": "Person",
"name": "Jacob Padilla",
"url": "https://jacobpadilla.com",
"image": "https://jacobpadilla.com/static/icons/about-me/jacob-padilla-headshot-1.jpg",
"affiliation": "New York University",
"gender": "Male",
"nationality": "American",
"description": "Jacob Padilla is an NYU Stern student, photographer, developer, and blogger based in the USA. He writes about Python, SQL, and a range of other topics.",
"sameAs": [
"https://www.instagram.com/jpjacobpadilla",
"https://x.com/jpjacobpadilla",
"https://www.linkedin.com/in/jpjacobpadilla",
"https://github.com/jpjacobpadilla",
"https://www.reddit.com/user/jpjacobpadilla"
]
}
}A great place to get some templates for writing these types of schemas for all sorts of pages is via the Google structured data examples. Also, when writing structured data for your website, I’d recommend copy and pasting it into a validator first to make sure that it’s formatted correctly.
After writing a structured document, you can put it in a special script tag nested within the head tag like such:
<head>
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Person",
…
}
</script>
</head>Meta Tags
The next important set of elements in a page’s head are the meta tags. There are so many meta tags out there, but below is a list of ones that I consider to be most important to have for SEO purposes.
Description
The description meta tag lets you suggest a description for your webpage when it shows up in search results like such:
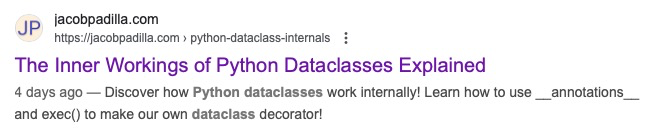
To add a custom description to a page, just set the name attribute of a meta tag to description and set the content attribute to your description like this:
<meta name="description" content="Your description here.">While these days, Google can generate custom titles and descriptions for its search results, if you write your own, more often than not Google will use it. This is generally better than letting Google create one for you since, chances are, you can write a better description for the page that will lead to a higher click-through rate.
To get the best chance of having Google (or other search engines) use your specified description instead of an auto-generated one, you should make sure it is under 155 characters long.
Encodings and Responsive Design
Search Engines will use these two meta tags to understand the specifications of your website. The first one specifies the encoding of your site, which in most cases will be UTF-8. The second one lets browsers (and search engines) know that your site is mobile-friendly - which is a must these days, considering how much traffic comes from phones…
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">Author
This meta tag is important for search engines to know who wrote something, as it can contribute to increasing the authority of a page:
<meta name="author" content="Jacob Padilla">Open Graph Protocol
The Open Graph Protocol meta tags are to let other websites, like social media sites or messaging platforms, display your page. This is related to SEO since some platforms like Google will occasionally display thumbnail images in search results or in places like Google Discover. It’s also important to get people onto your site, since having a page with a nice thumbnail will definitely increase the click-through rate of said page.
Below is an example of how I use the Open Graph tags to represent one of my articles:
<meta property="og:title" content="Handling Tasks in Asyncio Like a Pro">
<meta property="og:description" content="I first go over the basics of an Asyncio task object and then talk about all of the various ways to handle them and the pros and cons of each.">
<meta property="og:type" content="article">
<meta property="og:site_name" content="Jacob Padilla">
<meta property="og:image" content="https://jacobpadilla.com/articles/blog_posts/handling-asyncio-tasks/static/handling-asyncio-tasks.png">
<meta property="og:image:alt" content="Learn about all the ways to handle Asyncio tasks!!">
<meta property="og:image:width" content="1200">
<meta property="og:image:height" content="630">Depending on how a website displays a webpage link will determine what specific properties are actually used. For example, here is how the article shows up in IMessage with the above Open Graph tags:
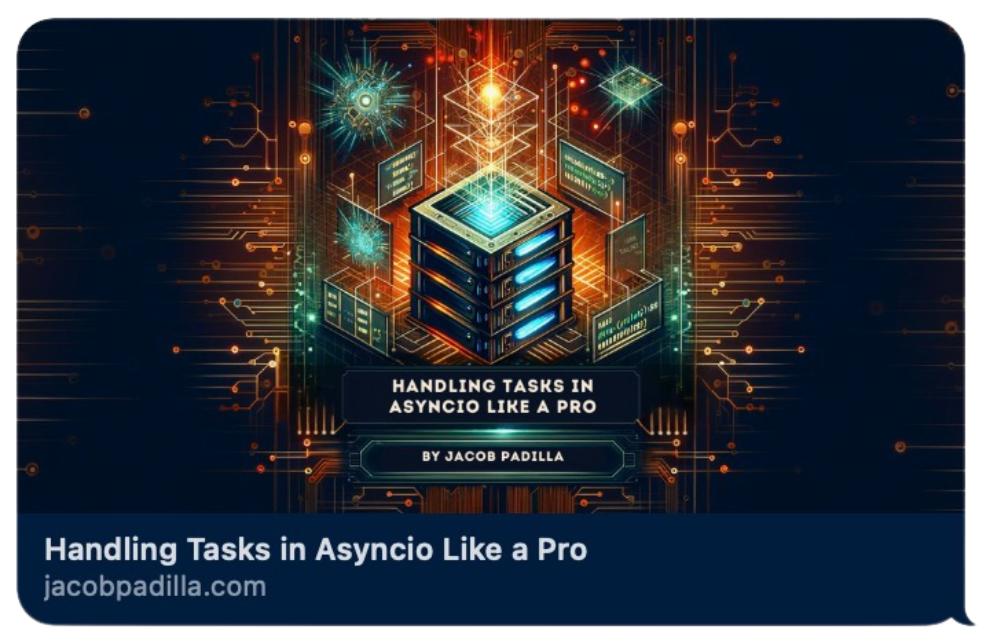
When writing Open Graph tags, I’d recommend using an Open Graph validator, which will show you how your webpage will appear on different apps!
Lastly, the Open Graph protocol also has specific properties for certain types of pages such as videos and articles:
<meta property="article:published_time" content="2024-02-28T00:17:05Z">
<meta property="article:modified_time" content="2024-10-27T00:00:00Z">
<meta property="article:author" content="Jacob Padilla">Twitter Images
While almost every site uses the Open Graph protocol, X/Twitter has its own protocol for displaying links. There’s more customizability that you can do specifically for Twitter, but for my articles, I pretty much just use the same information that I have for my Open Graph meta tags:
<meta name="twitter:card" content="summary_large_image">
<meta name="twitter:title" content="Handling Tasks in Asyncio Like a Pro">
<meta name="twitter:description" content="I first go over the basics of an Asyncio task object and then talk about all of the various ways to handle them and the pros and cons of each.">
<meta name="twitter:image" content="https://jacobpadilla.com/articles/blog_posts/handling-asyncio-tasks/static/handling-asyncio-tasks.png">
<meta name="twitter:site" content="@jpjacobpadilla">
<meta name="twitter:image:alt" content="Learn about all the ways to handle Asyncio tasks!!">Robots
The last meta tag I want to touch on lets you specify if/how web crawlers can index certain pages. It lets you specify whether the page should be indexed, and if it is indexed, how large the thumbnail previews should be for the page. To specify that your Open Graph thumbnail is big enough to be displayed as a large thumbnail on places like Google Discover, you can use the max-image-preview:large value in this tag. By signaling to Google that your thumbnail won’t look pixelated when displayed, you can increase chances that it will be shown to people via Google Discover.
<meta name="robots" content="index, follow, max-image-preview:large">Title Tag
Hopefully, you’re already using the title tag :). People say that you should keep the title of a page under 60 characters, but I like to keep my article titles under 55 characters as I don’t want any chance of Google altering it.
<title>How Python Asyncio Works: Recreating it from Scratch</title>Sometimes, Google may create its own title for your webpage in its search results. To avoid this, you should try to make sure that each page has only one h1 tag per page. This h1 tag should be very similar to the content of the title tag. If you have an article on your website, I would recommend making the title tag and the h1 tag the same.
Having a good title can also affect the click-through rate of your page. Ideally, you should include some of the most important keywords that describe what a webpage is about in the title. So, if you’re writing an article about SEO, include “SEO” in the title, and if you have a page about a specific location, include that location in the title as well. A good way to find titles that have high click-through rates is to search for similar pages to the ones on your site and see what the titles on the first page of search results have in common!
Canonical Link
The Canonical link is very important because it allows you to tell search engines what the main version of a page is. Let’s say that you have a web page where there can be many different query string parameters in the URL, or there are multiple versions of the URL that use different capitalization. When a search engine crawls that page, it may get confused and not know which URL to index. By specifying the main URL in the canonical link element, you can tell the search engine which version of the page to index. This will make sure that search engines don’t include fragments, query string parameters, or other versions of a URL.
<link rel="canonical" href="https://jacobpadilla.com/articles/recreating-asyncio">Async and Defer Scripts
One important part of technical SEO is decreasing page loading speed. I wrote a section on improving loading speed below, but there are a few simple things that you can do in the head of the page that I’ll talk about here.
One simple way to speed up the initial loading of your site is to add the async or defer keywords to the script tags in your web page. Without one of these attributes in a script tag, when a browser is parsing the HTML and reaches a script tag, it will pause, request the script, run the script, and then only after the script has finished running, will it continue to parse the HTML. Requesting the JavaScript from a server and then running it may take a few hundred milliseconds which can add up if you have a lot of script tags!
To solve this issue, I would recommend adding one of the following attributes to your script tags:
-
Asynctells the browser to request and then run the script in parallel to parsing the HTML. -
Defertells the browser to request the JavaScript, but then wait to execute the script until after the HTML is done being parsed. This can save a huge amount of time and also has the added benefit of ensuring that all of your HTML is loaded before any JavaScript may try to access it.
As for actually adding these to the script tags, just tack them on somewhere as an attribute like this:
<script defer src="/static/js/article.js?v=4"></script>DNS-Prefetch
Another simple speed improvement can be to preemptively get the IP address of certain websites that you know the browser will need to request at some point in the future. Two simple examples are prefetching the DNS records for a CDN (which may then be used to load images on the site) and prefetching the destination for any Google fonts.
<link rel="dns-prefetch" href="https://example-cdn.com">
<link rel="dns-prefetch" href="https://fonts.googleapis.com">Preconnecting
Preconnect is similar to DNS-prefetch, but it goes a step further by opening a TCP connection to the specified site before the user even asks for it. This can be great if you know there is a very high likelihood that the browser will need to send requests to another server, like maybe a third-party API.
<link rel="preconnect" href="https://example.com">Semantic HTML
Semantic HTML is all about writing clean HTML that a search engine can easily understand. One of the most important ways to improve the semantic HTML of a page is to use the proper container elements. Instead of using divs for containers, use more descriptive elements like footer, header, main, section, article, aside, nav, address, summary, and more.
Let’s take a look at some HTML that is not semantic:
<body>
<div id="header">
<div id="title">My Blog</div>
<div id="menu">
<a href="#home">Home</a> |
<a href="#about">About</a> |
<a href="#contact">Contact</a>
</div>
</div>
<div id="content">
<div id="article-title">Understanding Non-Semantic HTML</div>
<div id="article-body">
<p>Non-semantic HTML relies on generic tags instead of meaningful, descriptive elements.</p>
</div>
</div>
<div id="footer">
<div id="copyright">2025 All rights reserved.</div>
</div>
</body>Since the HTML isn’t using any descriptive tags, a search engine (and also probably you) has a much harder time interpreting what the page is about. However, if we update the same HTML, using semantic tags, we get the exact same page, but with the added benefit of web crawlers being able to understand the page better:
<body>
<header>
<a href="/">My Blog</a>
<nav>
<ul>
<li><a href="#home">Home</a></li>
<li><a href="#about">About</a></li>
<li><a href="#contact">Contact</a></li>
</ul>
</nav>
</header>
<main>
<article>
<h1>Understanding Semantic HTML</h1>
<p>Semantic HTML uses meaningful tags to describe content, improving accessibility, SEO, and maintainability.</p>
</article>
</main>
<footer>
<p>2025 All rights reserved.</p>
</footer>
</body>Another important thing to take into account when writing HTML is which h[number] tags to use for headings. Ideally there should only be one h1 tag per page - the most important header/title for a page. Then you can have a few more h2 tags and then even more h3 tags. These tags have nothing to do with the font size or boldness of the text, they are only for search engine semantics.
Adding more information about non-text-based content is also very important. The most important of these attributes to add to an HTML tag that isn’t usually seen by users is the alt attribute for image elements. This attribute is displayed if the image isn’t loaded, but it also lets search engines and, for accessibility purposes, screen readers know what the picture is about. Even a small sentence about what the image is, will help Google know that you are showing relevant images to the users on your page.
Optimizing Page Speed
According to Google, if a webpage doesn’t load within 3 seconds, about half of mobile visitors will leave and go to another site! Making sure that your website loads quickly is, therefore, extremely important. I’ve already touched on some small things that you can do in the head of the page, such as using async/defer to load javascript, DNS-prefetching, and preconnecting to other servers such as an API. However, I want to go over a few more easy ways to improve site performance in this section.
First, before trying to improve performance, you need a way to measure it. I’d recommend using Google's PageSpeed Insights tool, which will give you very useful data on how fast your site loads on a desktop and phone. This tool will also give you some tips on what specific things you can do to make your site faster!
While there are basically endless things that you can do to make sites faster, here are a few easy wins for most websites:
For starters, optimizing any images on your site by compressing them can have a big impact on how fast a page loads as images are often some of the largest assets that browsers need to download. Making your images as small as possible is a great start, but you can do even better by telling browsers to let your images load lazily. Usually, images on a page are loaded immediately when a user visits a page, which can slow down the initial loading of a site. However, with lazy loading, the browser will only load images just before the user scrolls to the spot on the page where the image is about to come onto the screen. To make an image load lazily, just add the loading=“lazy” attribute to an image element:
<img class="photography-img no-user-select" loading="lazy" src="static/photography/United States_39.webp" alt="A photo Taken by Jacob Padilla.">Another way to speed up your site, if it has large CSS or JavaScript files, is to “minify” them. Minifying these files is a process of compressing them into much smaller versions of themselves which can reduce the size by a noticeable amount. Reducing the size of these files means less bytes that need to travel from a server to each user, which in turn will increase the speed of your site for new visitors!
On the topic of static content, like images, CSS, and JavaScript, if you’re serving a lot of static content to a lot of users, you may also want to look into how you can serve this content faster. This is where a CDN (Content Delivery Network) can come in handy. A CDN is essentially a network of servers around the world that companies like Amazon and CloudFlare offer that can cache your static files and serve them to users much faster than a single server can.
Lastly, another way to speed up the initial load time of a site is by rendering as much of it as possible on the server as opposed to having to make a bunch of API calls just to load the basic data. This is one of the big downsides with a lot of JavaScript frameworks - just to load a simple page, the browser needs to run a bunch of JavaScript, which then sends more HTTP requests to an API. Then, the browser needs to wait to get the API responses, and only then can it put the data into the DOM for the user to see.
Robots.txt and Sitemaps
The next two things I want to talk about are important pages on websites that search engines can use to understand what and how to index your site.
Let’s start with robots.txt - this is a page on your site that is at the endpoint https://[website]/robots.txt. For example, this is my robots.txt page: http://jacobpadilla.com/robots.txt. Web crawlers, like Googlebot, use this page to figure out what it’s allowed to scrape and what it shouldn’t. If you don’t want certain parts of your website to show up in search results, you can add the pages to the robots.txt page.
Here’s a link to a more comprehensive guide on how to write a robots.txt, but in this article, let’s take a look at my robots.txt page:
User-agent: *
Disallow: /resume
Disallow: /error
Sitemap: https://jacobpadilla.com/sitemap.xmlThe first line, User-agent: * lets web crawlers know that the following rules are for all (*) bots. Then I have two rules that tell search engine web crawlers not to index two endpoints - 1. My resume, since I’d rather have my website show up in search results when people search for my website than my resume and 2. The error page, which doesn’t need to show up in search results.
Lastly, the robots.txt specifies the location of the website's sitemap, which is usually at https://[website]/sitemap.xml.
A website's sitemap is a place where web crawlers can essentially see a map of your website - it shows them all of the pages on your site so that they can all easily be found. In the sitemap, you specify the links to your webpages, the time that it was last modified, a suggestion to the web crawler of how often it changes (aka how often the page should be re-crawled), and the priority of the page, which is a suggestion to some web crawlers of which pages should be crawled first, which may be important if the website is large.
Here’s an example of what one such sitemap url looks like:
<url>
<loc>https://jacobpadilla.com/articles/time-travel-with-git</loc>
<lastmod>2024-03-23T03:08:33+00:00</lastmod>
<changefreq>monthly</changefreq>
<priority>0.8</priority>
</url>Since manually updating a sitemap would be a huge pain, a long time ago, I wrote some Python code to automatically query my website's database to get all of the articles and then use the lxml package to generate a new sitemap. While this exact code probably won’t work for you, I’m putting it below since it can probably be used as a template for some people.
from datetime import datetime
from lxml import etree
main_pages = [
"https://jacobpadilla.com/",
"https://jacobpadilla.com/articles",
"https://jacobpadilla.com/photography",
"https://jacobpadilla.com/contact"
]
urlset = etree.Element("urlset", xmlns="http://www.sitemaps.org/schemas/sitemap/0.9")
for url in main_pages:
url_element = etree.SubElement(urlset, "url")
etree.SubElement(url_element, "loc").text = url
etree.SubElement(url_element, "changefreq").text = "monthly"
etree.SubElement(url_element, "priority").text = "1.0"
# Articles
for mod_time, url in results: # results is a SQL cursor
url_element = etree.SubElement(urlset, "url")
etree.SubElement(url_element, "loc").text = "https://jacobpadilla.com/articles/" + url.lower()
etree.SubElement(url_element, "lastmod").text = mod_time.strftime('%Y-%m-%dT%H:%M:%S+00:00')
etree.SubElement(url_element, "changefreq").text = "monthly"
etree.SubElement(url_element, "priority").text = "0.8"
with open("../app/static/sitemap.xml", "wb") as f:
f.write(etree.tostring(urlset, pretty_print=True, xml_declaration=True, encoding='UTF-8'))Final Thoughts
While there are a lot of components to increasing site search ranking such as your sites domain authority, the quality of your content, and backlinks, optimizing your website so that crawlers can easily understand your content is an important piece to the puzzle. This article should be a good starting point for some of the most important things that you should include on the pages that you are trying to rank!