How Pandas DataFrames Manage and Store Data Efficiently
A few months ago, I became curious about how Pandas stores data in their DataFrames, so I spent some time reading through their source code and learned about Pandas’ internal BlockManager object. This object allows for some pretty interesting performance optimizations and totally changed how I conceptualize a DataFrame! Now that I’ve graduated college, I finally have time to write this quick article about how Pandas actually stores data in DataFrames.
DataFrame Basics
I think a lot of people (myself included) like to think of DataFrames as a dictionary of Pandas Series, which are wrappers around NumPy arrays. This can be a simple way to visualize a DataFrame since a lot of the operations are very similar to how a dictionary works – for example, getting a column in a DataFrame uses the same syntax as getting a value from a dictionary: df[‘column’].
If put into a diagram, here’s what the internal structure of the data would look like:
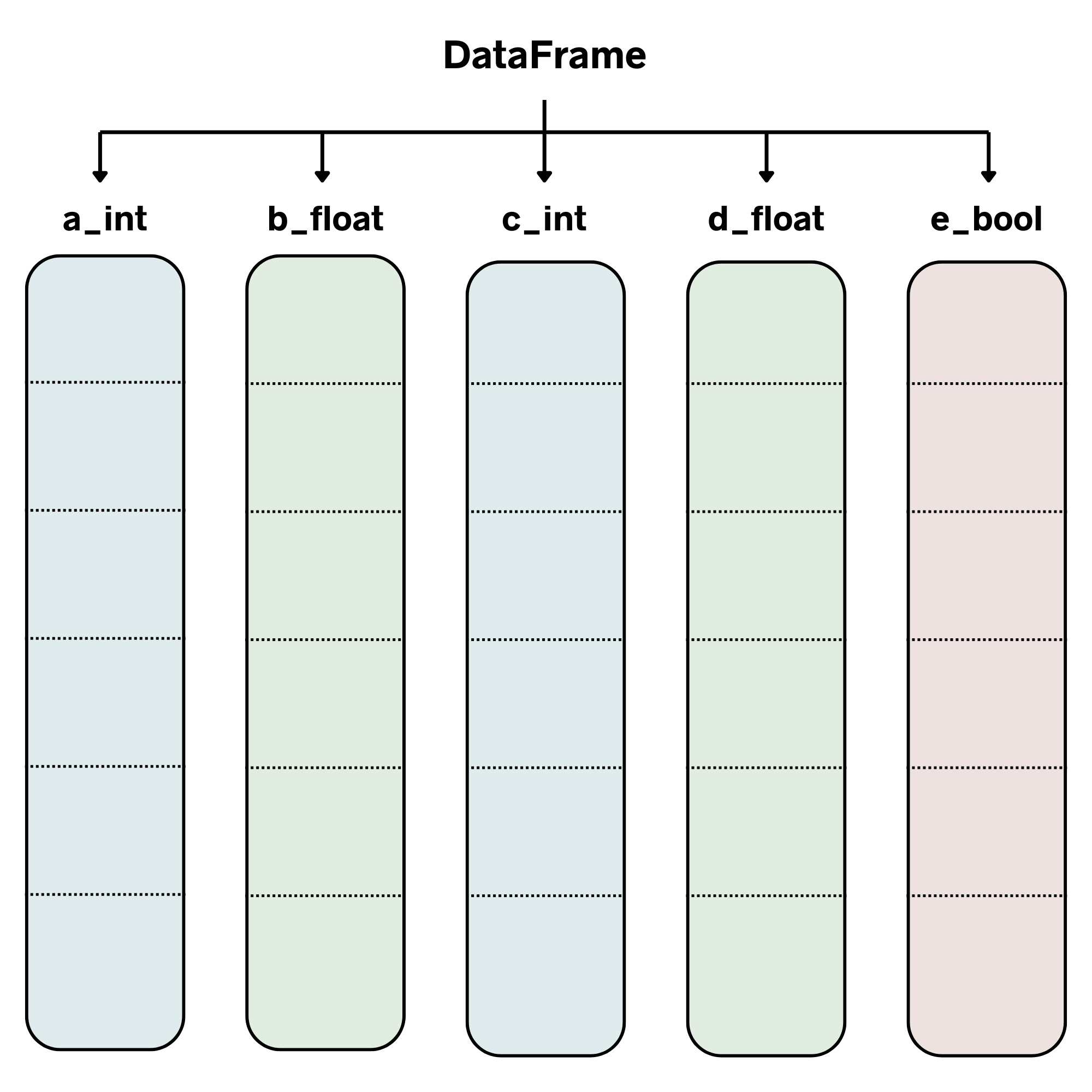
The BlockManager
The problem with storing each column in a separate array is that it’s memory-inefficient, prevents you from using fast vectorized operations between multiple columns, and can be especially slow for row-based operations. This is where the BlockManager comes into play. The BlockManager is an object that combines columns of the same data type into 2D arrays referred to as blocks. While this adds a bit of complexity to how a DataFrame works, it helps to solve the problems with using a single 1D array for each column.
With the BlockManager, here’s a better representation of how the above DataFrame is actually internally structured:
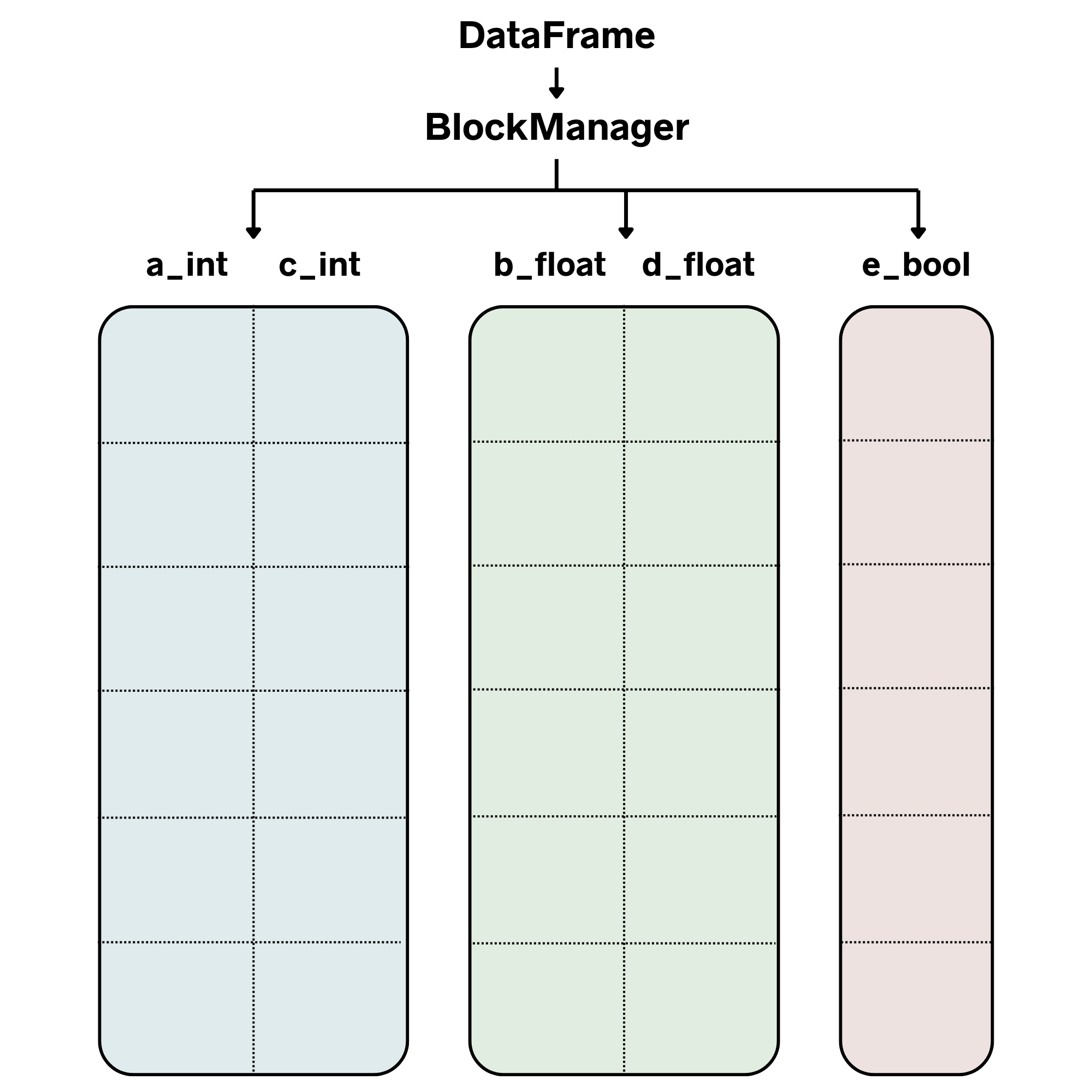
If we use Python to create the DataFrame that I’m depicting above, we can verify that each column is actually just a view of a larger NumPy array:
import pandas as pd
df = pd.DataFrame({
'a_int': [1, 2, 3],
'b_float': [1.5, 2.5, 3.5],
'c_int': [4, 5, 6],
'd_float': [4.5, 5.5, 6.5],
'e_bool': [True, False, True]
})With this DataFrame, we can get the NumPy array representing a column via the values attribute:
array = df['a_int'].valuesNow, if we use the base attribute on the array variable, we can see that the array is actually a view into the DataFrame’s int block:
array.baseOutput:
array([
[1, 2, 3],
[4, 5, 6]
])Another interesting thing to note is that you can actually see how the BlockManager object slices up a DataFrame via the _mgr attribute:
df._mgrOutput:
BlockManager
Items: Index(['a_int', 'b_float', 'c_int', 'd_float', 'e_bool'], dtype='object')
Axis 1: RangeIndex(start=0, stop=3, step=1)
NumpyBlock: slice(4, 5, 1), 1 x 3, dtype: bool
NumpyBlock: slice(1, 5, 2), 2 x 3, dtype: float64
NumpyBlock: slice(0, 4, 2), 2 x 3, dtype: int64Block Consolidation
When a DataFrame is created, Pandas automatically consolidates columns of the same data type into shared blocks. However, when adding new columns to a DataFrame after it’s been created, each new column is added as a separate block in the BlockManager. Over time, if you add a lot of new columns to an existing DataFrame, the performance of operations that span multiple columns will start to degrade.
Luckily, there are two easy ways to re-consolidate a DataFrame if it becomes too fragmented: One way is to create a copy of the DataFrame object with the copy method, and the second option, if you want to consolidate the DataFrame in place, is to use the _consolidate_inplace method.
After consolidating the DataFrame, you can verify that the columns are all joined together via the is_consolidated method:
df._consolidate_inplace()
df._mgr.is_consolidated() # Returns TruePerformance Improvements
Before looking into the Pandas source code, I never realized that DataFrames used 2D arrays behind the scenes and how much of a performance increase you can get from doing this. I tested out the speed difference between a DataFrame that had 1 block and another that had 250 blocks (both had the same number of columns) and found that the operations on the consolidated DataFrame were between 30% and 50% faster!
Pandas does a great job of hiding the complexity of the BlockManager when using DataFrames, so you probably won’t ever have to interact with it directly. That said, I think it’s pretty interesting to see how DataFrames structure their data compared to other methods like those used in relational databases.