Advanced Web Scraping With Python: Extract Data From Any Site
Posted on
In this article, I'm going to talk about some slightly more advanced techniques you can use to scrape data from websites. To start, I'll discuss how to best get and handle cookies and custom headers. Next, I’ll go over what TLS fingerprinting is and how to avoid it. I'm then going to talk about the common HTTP headers to be aware of and, lastly, how you can integrate exponential-backoff retrying when making HTTP requests.
If you haven't read my first guide to web scraping, I'd highly recommend it. In that article, I cover the basics of web scraping, including scraping client-side rendered sites via private APIs and parsing sites rendered on the server. These two techniques are the building blocks for the topics in this article.
Handling Cookies 🍪
Cookies are little key-value pairs stored on your browser in an SQLite database. They can be created via client-side Javascript or, more regularly, are set via the HTTP response header Set-Cookie. Once created, the cookies for a website are sent in a header called Cookie for every subsequent request made to that website. Cookies can be used for many things, but two of the most common use cases would be to 1. authenticate requests and track clients and 2. Keep track of user sessions.
While some cookies, like the Google Analytics ones, aren’t checked by the website’s server on each request, many cookies are looked at and verified by the server during each request, and thus, if not included, will result in an error.
Sometimes, especially when first developing a scraper, you may be able to get away with copying the cookies that your browser is using by going to Inspect Elements > Application > cookies. However, many cookies often expire, and thus, copying and pasting them into your program wouldn’t be a long-term solution.
Fortunately, pretty much all of the HTTP request packages in Python have some sort of built-in session object that keeps track of cookies for you. In the widely-used requests package, you can create an object called requests.Session. Once instantiated, this object automatically stores cookies set via HTTP responses and then sends them in future requests, just like a browser. Session objects also offer additional benefits, such as the ability to set default headers for all requests and to keep TCP connections alive using the keep-alive response header.
Let’s look at how request.Session works with the example below. We’re sending a request to YouTube, which, on the initial visit to the website, sets a few cookies:
import requests
# Create a session object
session = requests.Session()
# Make a request to Youtube
session.get('https://www.youtube.com')
# Print cookies stored in the session
print("Cookies after setting them:")
for cookie in session.cookies:
print(f'{cookie.name} = {cookie.value}')These are the cookies that are set when going to Youtube for the first time (slightly changed for privacy):
Cookies after setting them:
GPS = 1
VISITOR_INFO1_LIVE = bt6OfdFmwPv
VISITOR_PRIVACY_METADATA = GdFVUfwWxIEGLaGXb%3D%3D
YSC = FsZpF9k7OyQNow, if you want to send additional requests to YouTube, you can do so from the session object, which will automatically send the above cookies. This is very helpful as YouTube probably checks these cookies on its server since it wouldn’t have set them otherwise.
Session Cookies
One common use case for cookies is storing session IDs or tokens. They enable you to log in and out of websites as well as tell the server if you have access to certain pages/data. If you want to scrape data from sites requiring users to be logged in, you’ll need to ensure that the requests you're sending contain a session cookie (assuming the website uses cookies for authentication, which 99% do).
Besides copying the session cookie from your browser’s development tools, which is a temporary solution as no website should let you stay logged in forever, you’ll need to get the session cookie programmatically.
To programmatically recreate a website's login process, you’ll need to navigate to your browser developer tools and then go to the “Network” tab. Once there, you can log in to the website normally and then view the request that was sent to the server right after clicking the “Log in” button. Once you find the request that sends your login credentials to the server and responds with a Set-Cookie header containing a session ID cookie, you can recreate the request in Python using the request.Session object from above.
Let’s see all of this in practice, using the example website I created in my article about creating a user login system with Flask. This website has three pages: There is a login page: localhost:5000/login, a register new user page: localhost:5000/register, and there is also one page that requires you to be logged in: localhost:5000/.
First, let’s see what happens when we send an HTTP request to / without any session cookies:
import requests
session = requests.Session()
resp = session.get('http://localhost:8000/', allow_redirects=False)
print(resp.status_code)
print(resp.headers['Location'])The above code gives us the following output:
302
'/login'This is expected since, in the article where I wrote this code, I added logic whereby if a user tries to go to a page that they do not have access to, it will automatically redirect them to the login page. The way that redirects work in the HTTP protocol is if the server responds with a 302 status code, the client will look at the HTTP response headers (sent by the server) and redirect the client to the endpoint in the Location header, which in this case is /login.
To figure out how to recreate the login request, let’s examine the request that the browser does right after logging in:
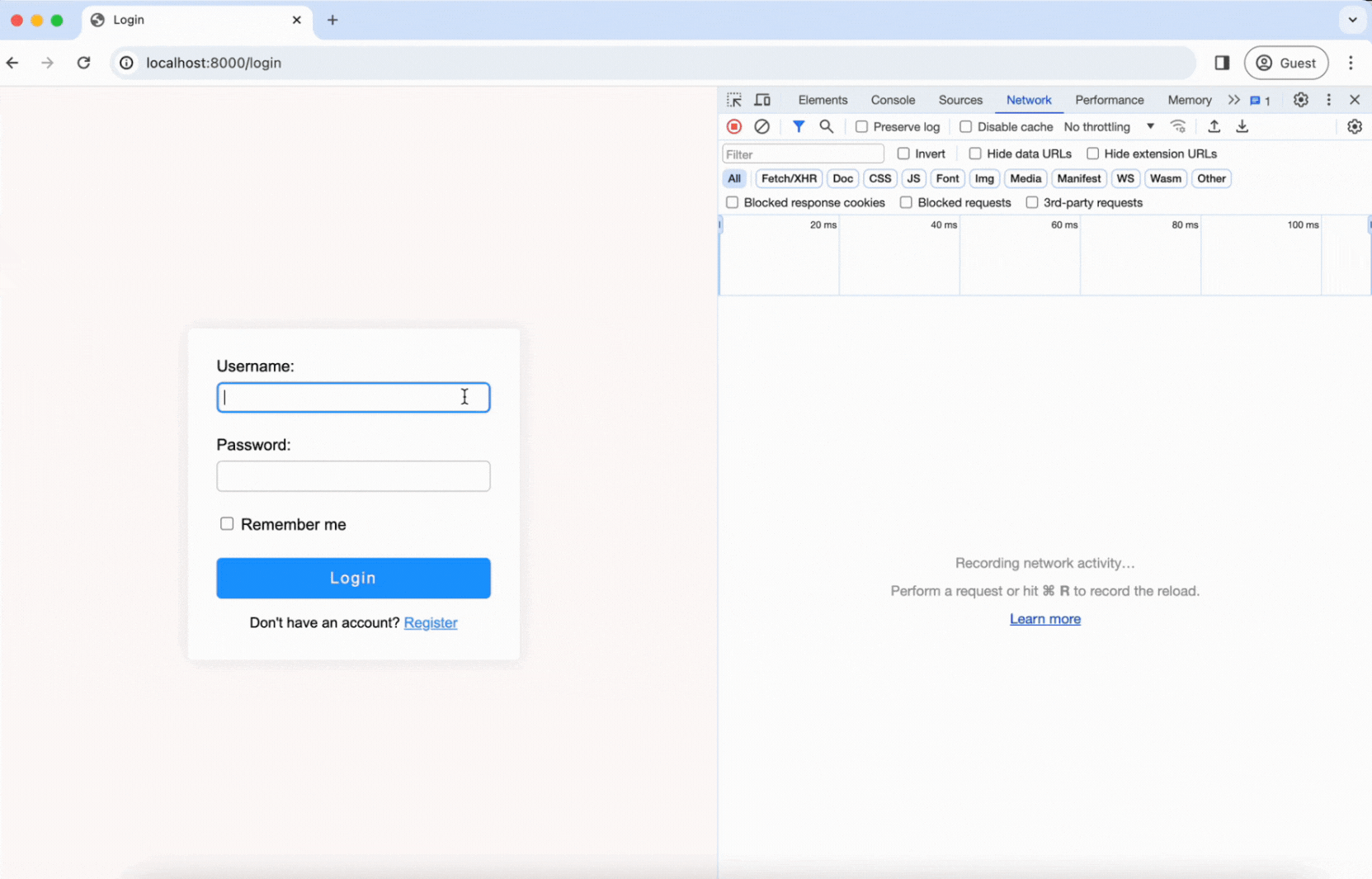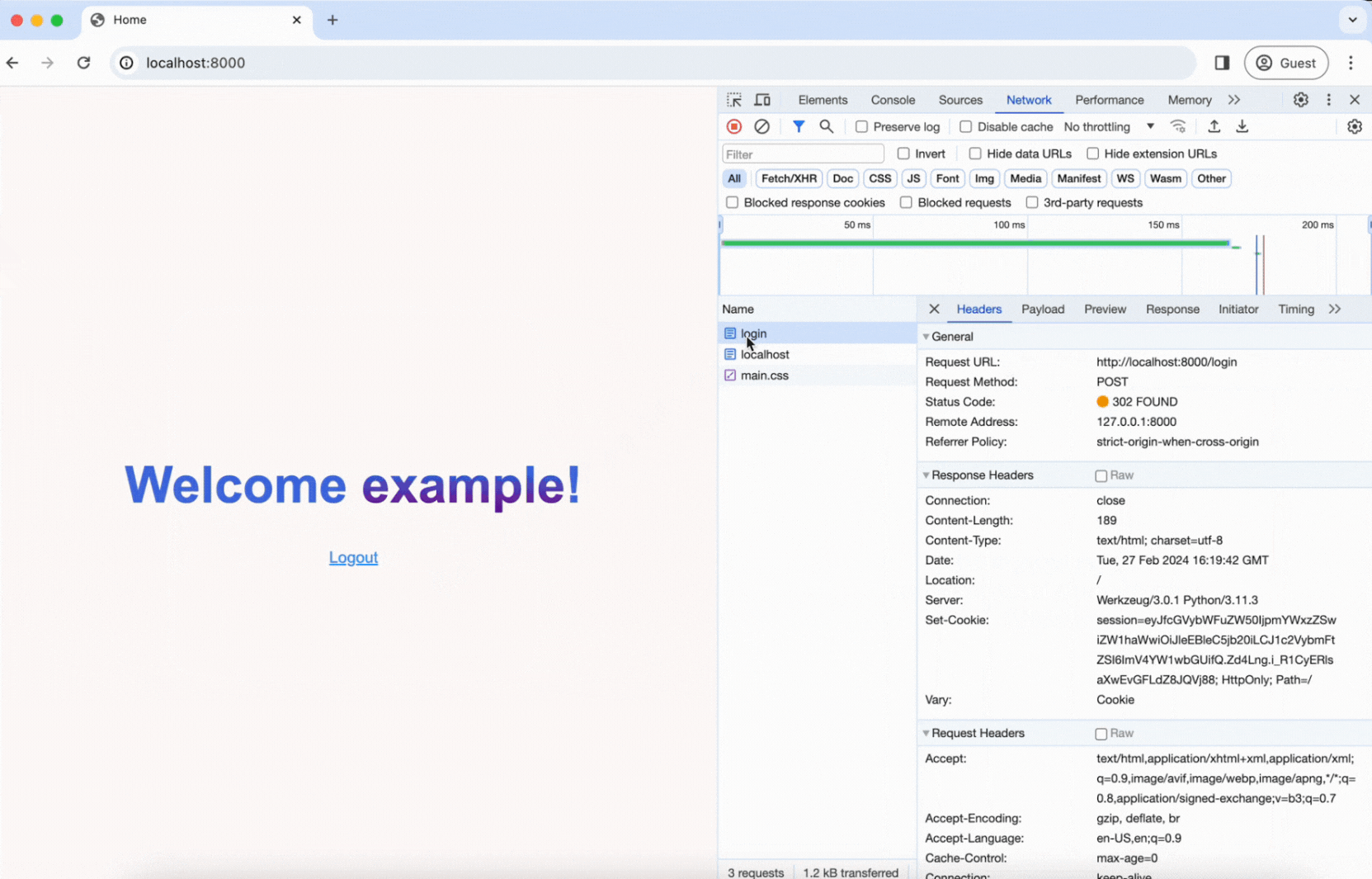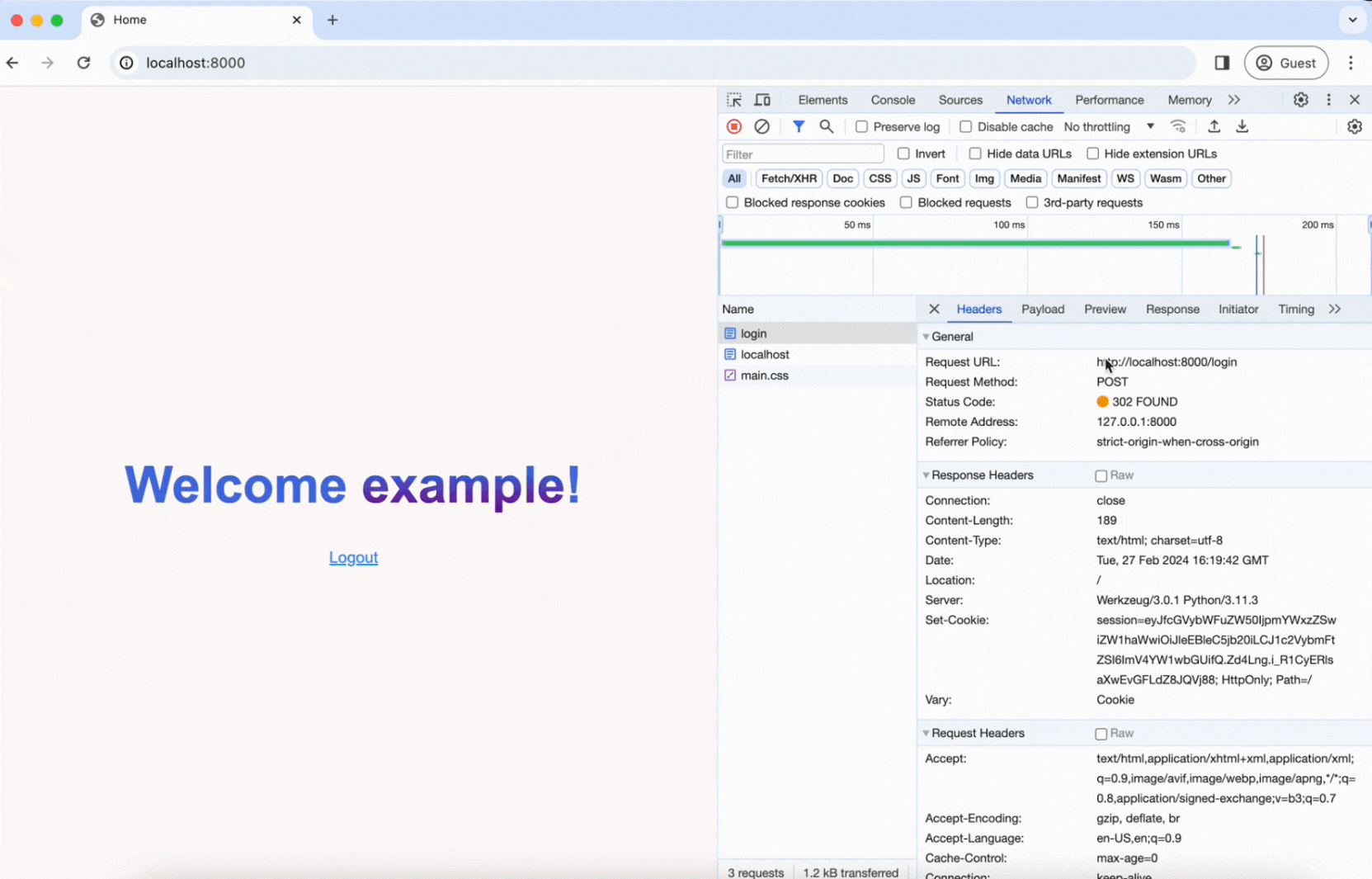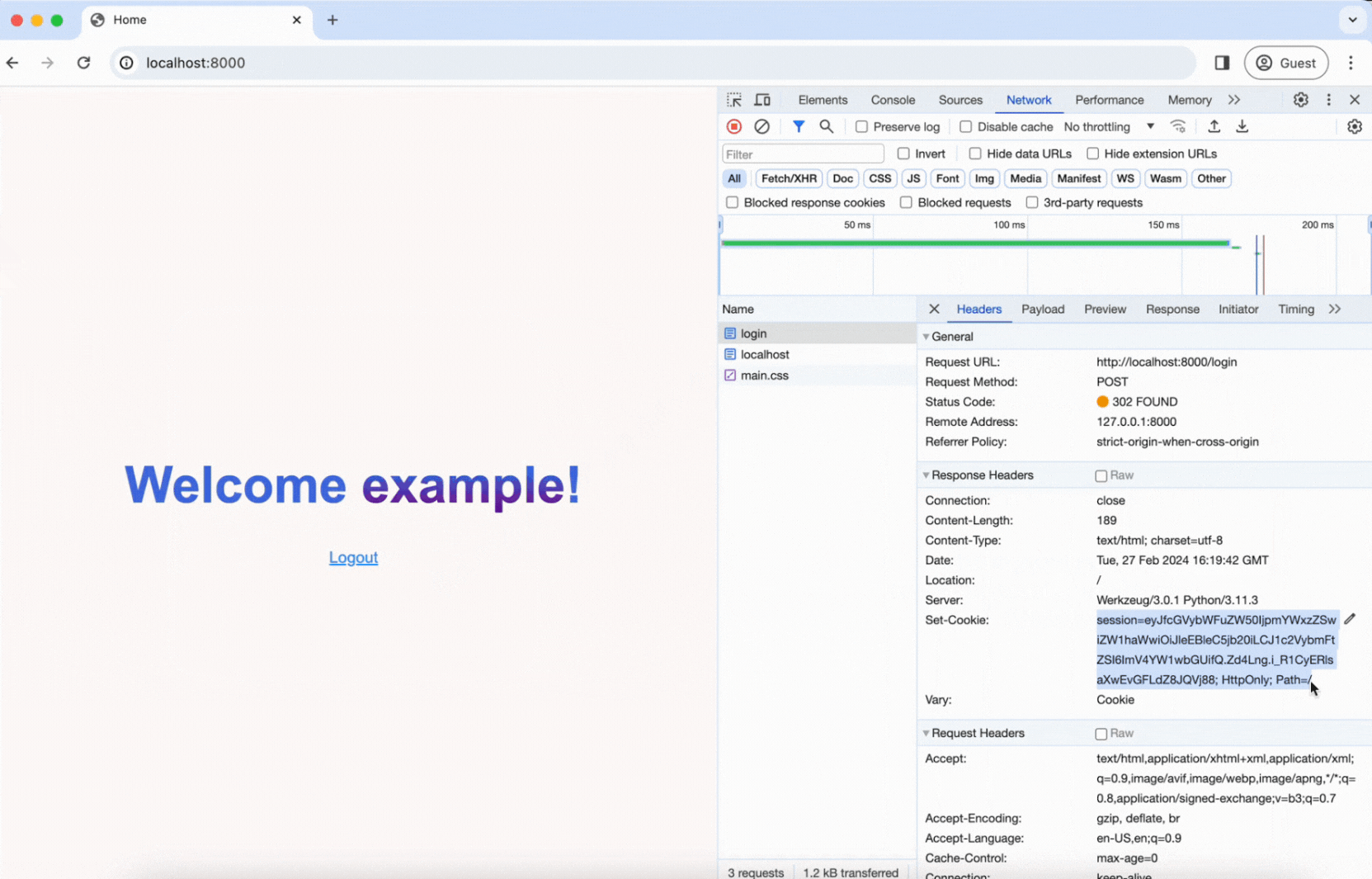
As you can see in the video, right after submitting the login form, a POST request is sent to the /login route. The username and password are sent in the body of the request, and you can see that the server responds with a Set-Cookie header, which gives us our session cookie!
Now, let’s copy and paste the cookie into our Python code and see what happens when we send an HTTP request to the login-only page. Note that the session cookies are stored in a dictionary-like object, so we can use the update method to add new ones.
import requests
session = requests.Session()
session.cookies.update({'session': 'eyJfcGVybWFuZWF0IjpmYWxzZSwiZW1haWwiOiJlefEBleC5jb20iLCJ1c2VygmFtZSI6ImV4YW1wbGUifQ.Zd4Lng.i_R1CyERlsaXwEvGFLdZ8JQVj88'})
resp = session.get('http://localhost:8000/')
print(f'The response status code is {resp.status_code}')
print(resp.text)Output:
The response status code is 200
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" href="/static/main.css">
<title>Home</title>
</head>
<body>
<h1>Welcome <span class="gradient-text">example</span>!</h1>
<a class="text-link" href="/logout">Logout</a>
</body>
</html>The response status code is now 200, which means the request was successful, and the request also sent back the correct HTML markup.
Now, instead of copy and pasting the session cookie into our code, let’s put this all together and programmatically log in:
import requests
session = requests.Session()
payload = {
'username': 'example',
'password': 'exampleusername'
}
session.post('http://localhost:8000/login', data=payload)
resp = session.get('http://localhost:8000/')
print(f'The response status code is {resp.status_code}')
# print(resp.text) → Prints out the same as above...Output:
The response status code is 200CSRF Tokens
CSRF tokens, or Cross-Site Request Forgery tokens, are often included in requests that perform operations while a user is logged in. These tokens ensure that the client has intentionally initiated the request, guarding against malicious websites that might attempt to exploit the user's authentication status on another website. Without CSRF tokens, a malicious website could send a request to another website where the user is logged in, and since the browser automatically sends all cookies associated with a website, the target website's server would think that the client is logged in.
That’s the basic theory behind CSRF tokens, but actually, when a website sets a cookie, it can add a special attribute to the cookie called SameSite that tells the browser to only send the cookie if a request originates from navigation to the website (such as clicking on the website from Google search) or while on the website (navigating between pages). This helps prevent CSRF attacks, but it isn’t foolproof as some websites may not properly set the SameSite attribute. Nevertheless, CSRF tokens are still a thing, so you need to know how to deal with them.
CSRF tokens are typically sent from the client to the server in one (or two for a double-submit CSRF token pattern) of three places:
- Hidden Form Fields: When the form is submitted, the token is automatically sent as part of the form data.
- HTTP Headers: Tokens can also be sent as part of the HTTP request headers. Generally, the header may be named something like
X-CSRF-Token. - Cookies: Tokens can also be stored in cookies if the website uses the Double-Submit pattern.
The implementation of CSRF tokens varies amongst websites, but let’s say that in a theoretical website, we notice, by examining the login request in DevTools, that the login request is using a double-submit CSRF token pattern and thus, is sending the CSRF token in both a hidden HTML form input element and as a header in the request.
The HTML would look something like this, with a hidden CSRF token that will automatically get sent to the server when submitting the form:
<form action="/login" method="POST" id="login-form">
<input type="hidden" name="csrf_token" value="randomlyGeneratedToken12345">
<input type="text" name="username">
<input type="password" name="password">
<button type="submit">Log In</button>
</form>To successfully log in to this theoretical website using Python, we first need to send a GET request to the page with the login form, parse the HTML using a package such as Lxml or BeautifulSoup to get the CSRF token, and then add the CSRF token to our programmatic request in the body and head of the request:
import requests
from lxml import html
# Start a session
session = requests.Session()
# Fetch the login page
login_page_response = session.get('https://example.com/login')
login_page_html = html.fromstring(login_page_response.text)
# Extract the CSRF token
csrf_token = login_page_html.xpath('//form[@id="login-form"]/input[@name="csrf_token"]/@value')[0]
# Login credentials and the CSRF token
payload = {
'username': 'your_username',
'password': 'your_password',
'csrf_token': csrf_token,
}
# Adding the CSRF token to the request headers
headers = {
'X-CSRF-Token': csrf_token,
# Other headers such as User-Agent would also go here…
}
# Submit the login form
response = session.post('https://example.com/login', data=payload, headers=headers})Use Selenium for the Hard-to-Get Tokens
CSRF tokens are just the tip of the iceberg; sometimes, a website may use many tokens generated via a complex sequence of requests or very obfuscated client-side Javascript. While it’s theoretically possible to reverse engineer any website with just HTTP requests, sometimes I like to use Selenium to do the heavy lifting to get these complex tokens. After Selenium gets the tokens, you can quit the driver and pass the tokens into an HTTP session object.
This takes the best of both worlds in the sense that Selenium will pretend to be a real browser and handle all of the complex token generation and then once you get everything, you can feed the cookies and headers into a lightweight and fast HTTP-based request module for the actual scraping. If you want to learn more about packages like requests and beautifulsoup, check out this article comparing different Python-based web scraping packages!
The Selenium code to log in or load a webpage to get these tokens will be a little bit different from site to site, but here’s the general structure that you can use:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import requests
import time
# Your login details
USERNAME = "your_username"
PASSWORD = "your_password"
# URL details
login_url = "https://example.com/login"
target_url = "https://example.com/after_login"
# Initialize Selenium ChromeDriver
driver = webdriver.Chrome()
# Open the login page
driver.get(login_url)
# Find the username and password fields and submit button
username_field = driver.find_element_by_name("username")
password_field = driver.find_element_by_name("password")
submit_button = driver.find_element_by_xpath("//button[@type='submit']")
# Enter login details and submit form
username_field.send_keys(USERNAME)
password_field.send_keys(PASSWORD)
submit_button.click()
# Some artificial wait
time.sleep(5)
# Now that we're logged in, we can grab the cookies and headers
cookies = driver.get_cookies()
# Clean up: close the browser window
driver.quit()
session = requests.Session()
# Transfer cookies from Selenium to the Session object
for cookie in cookies:
session.cookies.set(cookie['name'], cookie['value'])
# Now you can use the session object to make requests as the logged-in user
response = session.get(target_url)Avoid TLS Fingerprinting
One of the more challenging things to get around in web scraping is TLS fingerprinting. When you make an HTTPS request, during the TCP handshake, the client and server need to exchange information, such as which TLS versions and cipher suites the client supports to do the encryption over. By taking all of the information sent by the client, the web server can create a fingerprint to describe the client’s TLS configuration. Websites can then use this fingerprint to compare against a database of known fingerprints, enabling them to infer the request's source with a high degree of accuracy.
One prominent company that implements this approach is CloudFlare. They can use it to tell if the requests are being sent from a commonly used browser such as Chrome or Safari, or if it was sent with a TLS configuration commonly used with the Python requests module or other HTTP tools.
The only way to get around this is by emulating TLS configurations of popular browsers. This involves operations at a lower level of the network stack, which are not typically supported by high-level packages like requests. However, luckily for us, there is a great package in Python called curl_cffi. This package has a very similar interface to the requests module, but when you send an HTTP request, you can specify what TLS configuration to imitate!
Let’s say that I want to send a GET request to a website and pretend to be sending it from Safari:
I would just install curl_cffi:
$ pip install curl_cffiAnd then send the request with one of the impersonation options found in their documentation:
from curl_cffi import requests
resp = requests.get(url, impersonate="safari")This request will now impersonate the TLS fingerprint from the latest version of Safari!
curl_cffi also has a session object exactly like the requests package, so everything I discussed in the above sections still works.
Headers to Watch Out For
When a browser sends HTTP requests, it automatically tacks on a bunch of headers to each request. Some of which are commonly checked by web servers to verify the validity of a request.
In Python, the requests package automatically sends the following headers in a GET request:
'Host': '[The host. Example: jacobpadilla.com]'
'User-Agent': 'python-requests/[package version]'
'Accept-Encoding': 'gzip, deflate'
'Accept': '*/*'
'Connection': 'keep-alive'These headers are obviously not at all what a browser will normally send, which can make your request seem very suspicious. Notably, the User-Agent header being set to python-requests/[package version], is very different from a normal user agent which would look something like this:
Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1Now that we’ve covered how different the headers are in requests and other popular HTTP packages, let's dive into the headers that web servers generally check and, therefore, are important to change.
Referer
The Referer header tells the browser what website the user came from. For example, if the user found a website from Google and subsequently clicked on the link to get to the website, the referer header would be www.google.com. If you send a request without a referer, it could be suspicious, as browsers will automatically send this header if you are navigating around a site.
User-Agent
Another very commonly checked header by web servers is the User-Agent header. Browsers send this in every request, which gives servers information about the browser and computer that sent the request. Information such as the device type and model, operating system, and browser name and version are all squished into the user agent.
When adding a user agent to the list of headers to send in a request, you can either get the user agent from your computer's browser or use a package such as fake-useragent (for Python) to generate random ones:
from fake_useragent import UserAgent
ua = UserAgent()
print(ua.safari)Output:
Mozilla/5.0 (iPhone; CPU iPhone OS 15_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.0 Mobile/15E148 Safari/604.1Client Hints
Client hint headers are a set of headers that tell the server more about the computer sending the request. Currently, Chrome is the primary browser that supports these headers. If you’re planning on mimicking the TLS fingerprint of Chrome, you should definitely include these headers. However, other big browsers like Safari and Firefox have also expressed their intention to support these headers soon. By default, Chrome sends three client hint headers in every GET request which look something like this:
Sec-Ch-Ua: "Google Chrome";v="117", "Not;A=Brand";v="8", "Chromium";v="117"
Sec-Ch-Ua-Mobile: ?0
Sec-Ch-Ua-Platform: "macOS"There are actually over 20 client hint header types that the browser can send. Here's how it works: If a web server wants these extra client hints to analyze, it will add the Accept-CH header in the response of a client's HTTP request. This header will contain a list of client hints that the server wants/accepts. One telltale sign that you need to pay close attention to these headers is if the server responds with the Accept-CH header, as this means that they are probably using these client hints to either build a fingerprint around your request or to do other things like verify the client hints against other headers such as the User Agent.
An example of an Accept-CH header in an HTTP response is:
Accept-CH: DPR, Width, Viewport-WidthThe example header specifies that the server requests the client to send the DPR (Device Pixel Ratio), Width (width of the image in CSS pixels), and Viewport-Width headers in subsequent requests to better adapt the response to the client's device.
The easiest way to get these client hints right is to examine the requests in a browser’s development tools to see what the browser does. Just make sure that these hints align with your other headers like User-Agent.
Retry Requests
Sometimes, you send a request that may encounter network issues, random server errors, or even rate limiting by the server. In these cases, it’s probably a good idea to wait a bit and then try resending the request.
Generally, I like to use an exponential backoff wherein I send a request, and if it doesn’t go through, wait a few seconds and try again; if that one fails, wait a minute or two and try for a final time. Of course, this varies a lot from site to site. If the site doesn’t require you to be logged in and you are getting blocked/rate-limited, instead of waiting, you could switch the IP address from which you are sending the requests via a proxy. However, if it’s a site that requires you to be logged in, like Instagram, you may want to wait hours before trying another action.
There are many third-party packages to do this, however, there is actually a built-in way to achieve this retrying in the Python requests module:
from urllib3.util import Retry
from requests import Session
from requests.adapters import HTTPAdapter
s = Session()
retries = Retry(
total=3,
backoff_factor=1,
backoff_jitter=1,
allowed_methods={'GET'},
)
s.mount('https://', HTTPAdapter(max_retries=retries))The session.mount method lets you add adapters to specific websites or protocols; in this case, any request to a website that uses HTTPS will try to send the request at most 3 times using the Retry adapter.
The backoff_factor is calculated in seconds via the following formula:
{backoff factor} * (2 ** ({number of previous retries}))Then, you can add an extra randomness component to this “sleep” via backoff_jitter which extends the backoff sleep time by a number between 0 and the value of backoff_jitter.
Conclusion
Keeping these techniques in your back pocket while mining data from the internet will hopefully help you build web scrapers faster and make them more efficient. In this article, I talked a lot about Inspect Elements/browser development tools. If you want to learn more about Chrome's Developer Tools, check out my article that goes over some of the hidden gems in Chrome DevTools!